Paylaş

Informatica PushDown Optimizasyon Nedir?
Merhabalar, bugün sizlere Informatica’nın çokta bilinmeyen özelliklerinden biri olan PushDown Optimization’dan bahsedeceğim.
Push Down Optimizasyon’ın amacı iyi performans elde etmek için sunucular arasındaki yükü dengelemektir. Yani Informatica’da yaptığımız mapping’lerin Informatica Server’ındaki yükünü azaltmak ve yapılması gereken işi bir nevi Database’e yaptırmaktır.
Şimdi aşağıdaki resimli örneklerle bunu nasıl yaptığımıza bakalım ..
 Workflow seviyesine gelip ilgili Session’ının içerisine girdiğimiz zaman burada PushDown Option seçeneğinden,
Workflow seviyesine gelip ilgili Session’ının içerisine girdiğimiz zaman burada PushDown Option seçeneğinden,
To_Source ya da To_Target olarak seçtiğimizde Informatica Mapping’inde kullandığımız transformation’ları SQL sorgu mantığına çevirir ve hedef veritabanına SQL sorguları gönderilir.
3 çeşit PushDown Optimization vardır :
1) Source-side PushDown Optimization
Source Side : Sorguya çevirebildiği transformation’ları DB’ye göndermek üzere sorguya çeviriyor , çeviremediği transformationlarda(Rank Transformation , Mapplet gibi) ya da farklı veritabanlarından gelen source’ları gruplayamadığı için kesiliyor.
2) Target-side PushDown Optimization
Target Side : Workflow’da session bazında ayarlanır. Target’tan başlayarak Source’a doğru PushDown Optimization yapar.
3) Full PushDown Optimization
Full Side : Dikkat edilmesi gereken nokta Mapping’te kullanılan Source’ların aynı DB’de olması koşuludur. Yoksa Full PushDown Optimization yapılamaz.
Örneğin bir Products tablomuz olsun , bunların Client_No, Product_No, Principle_Amount alanları olsun. Informatica’da PushDown Optimization yapmak için;
To source’u seçtiğimizde üreteceği sorgu ,
select client_no , product_no , sum (principle_amount) from products group by client_no , product_no
To Target’ı seçtiğimizde üreteceği sorgu aşağıdaki gibi olacaktır.
insert into dummy as select client_no , product_no , sum (principle_amount) from products
Şimdi bir başka örneği inceleyelim , Workflow seviyesinde ilgili session.ının bize döndürdüğü sorguyu,
- adım PushDown Option seçeneği (To_Source – To-Target – Full ) seçip ,
- adım Preview Result For Connection’ı seçtikten sonra aşağıdaki gibi bir yapıyı görüntülemiş oluruz.
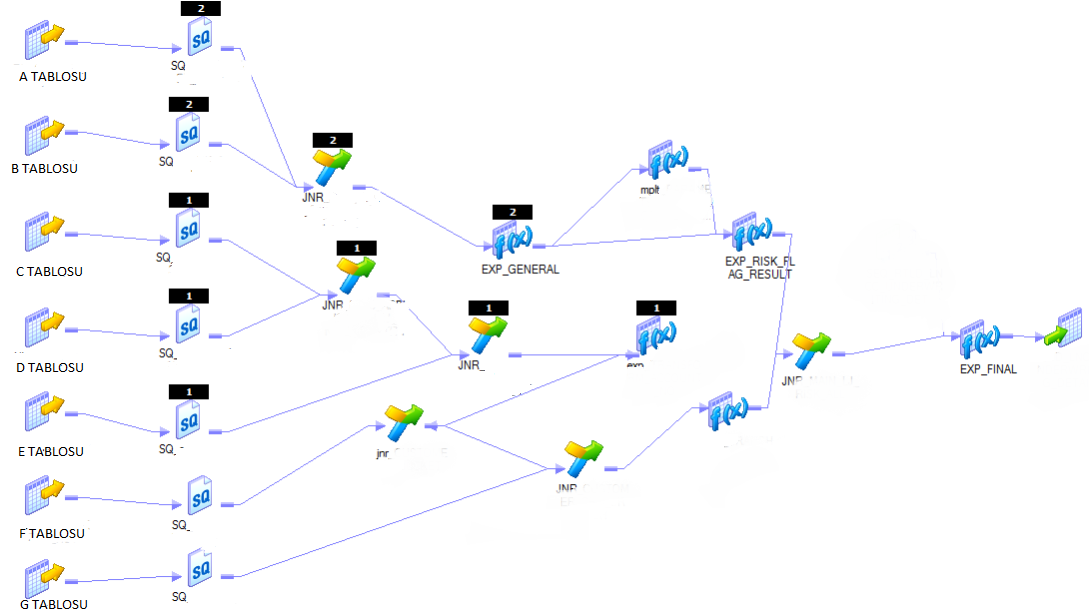
Oluşturduğu sorgular aşağıdaki gibi Group1 ve Group 2 şeklinde ayrılmıştır. Burada Group_1‘in temel mantığı , Group_1 source.ların Db’leri aynı , Group_2‘deki source.ların DB.leri aynı olduğu için bunları kendi arasında gruplandırmıştır. Sorguya dönüştürebildiği transformationların sorgusunu da aşağıdaki şekilde görebiliriz.
Group 1 :
SELECT * FROM C_TABLOSU INNER JOIN D_TABLOSU ON (C_TABLOSU.ID =D_TABLOSU.ID) RIGTH OUTER JOIN E_TABLOSU ON (E_TABLOSU.ID = C_TABLOSU.ID)
Group 2:
SELECT * FROM A_TABLOSU LEFT JOIN B_TABLOSU ON (A_TABLOSU.ID = B_TABLOSU.ID)